Integriertes Datenmanagement
- Details
- Erstellt: 30. Oktober 2008
Überblicken Sie Ihre Datenbestände auf allen Plattformen? 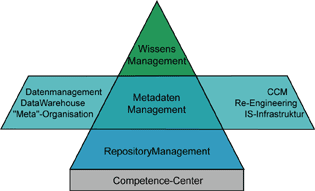
In allen Unternehmen stehen heute umfangreiche Datenbestände zur Verfügung. Sie sind über Jahrzehnte hinweg in unterschiedlichen Projekten entstanden. Sie sind nicht mehr nur zentral abgelegt, sondern in heterogenen Umgebungen den heutigen Anwendungserfordernissen entsprechend auf unterschiedlichen Systemplattformen vorhanden. Sie stammen aus unterschiedlichen Quellen, werden zwischen den Systemen transferiert und kopiert und basieren nur in seltenen Fällen auf einer gemeinsamen Datenarchitektur.
Der Informatiker Max Vetter hatte in den 80-er Jahren als Jahrhundertproblem der Informatik 'die Bewältigung des Datenchaos, das infolge unkontrolliert gewachsener Datenbestände fast überall entstanden ist' definiert. Das Jahrhundert, das er meinte, ist zuende. Ist das Problem inzwischen gelöst?
Auch heute kämpfen viele Unternehmen mit Redundanzen, Synonymen und Homonymen als Altlasten und hinterfragen die Konsistenz Ihrer Daten über die verschiedenen Systeme (Datenbank- und Dateisysteme in unterschiedlichen Rechnerumgebungen) hinweg.
Dem Überfluss an Daten steht oft genug ein Informationsmangel gegenüber hinsichtlich:
- Beschreibung und Kontext
- Korrektheit
- Vollständigkeit
- Aktualität
- Verwendung.
Die Vielzahl parallel laufender Projekte und die Notwendigkeit, auf die Anpassungswünsche der unterschiedlichen Fachbereiche schnell, flexibel und separat eingehen zu müssen, lassen Forderungen nach einer Verbesserung der Gesamtsituation und Reduzierung der enormen Koordinationsaufwände aufkommen.
Der Lösungsansatz Ein integriertes Datenmanagement in einem zentralen DataDictionary oder Repository wird auch in Ihrem Unternehmen zum Erfolg führen.
Ein solches integratives Gesamtsystem wird eine verbesserte Informationsversorgung ermöglichen und die Hauptaufgaben eines Datenmanagements gewährleisten:
- Schaffung einer einheitlichen Begriffswelt innerhalb des Unternehmens.
- Stabile bereichsübergreifende Datenhaltung.
- Verfügbarkeit eines zuverlässigen Informationsangebots für alle Aufgabenträger.
- Unterstützung bei der Entwicklung und Pflege von Datenmodellen.
- Planungsgrundlage für den langfristigen Informationsbedarf.
- Strategische Basis für eine durchgängige Datenarchitektur.
Mit der unternehmensweiten, redundanzfreien und möglichst sprachunabhängigen Ablage aller Datenobjekte im zentralen DataDictionary/Repository entsteht eine Umgebung für die Erstellung, Beschreibung und Verwaltung der Datenbestände. Ergänzt um sprach- oder datenbankspezifische Elemente erfolgt die Generierung konsistenter physischer Datenbeschreibungen für Anwendungen und Datenbanken aus dem zentralen Informationspool.
Die Vorgehensweise
Da es um die Optimierung bestehender Systeme geht, ist die zentrale Aufgabe des ersten Projektschrittes die Übernahme der bestehenden Datenelemente und -strukturen, sei es aus Copy-Bibliotheken, Datenbank-Katalogen, Programmsourcen, etc. oder auch aus anderen untergeordneten (gfs. toolspezifischen) Dictionary-Systemen. Ein weitestgehend maschinelles Verfahren mittels entsprechender Interfaces garantiert einen überschaubaren zeitlichen Rahmen für diese Arbeiten.
Die im Übernahmeverfahren erkannten und gekennzeichneten Redundanzen, Synonyme und Homonyme lassen sich anschließend transparent verwalten und in Planungen und Aktionen zu deren Eliminierung einbinden. Mit optionalen nachfolgenden Projektschritten werden wiederverwendbare Datenobjekte und generelle Datentypen herausgearbeitet.
Durch die maschinelle Generierung eines 'Status quo' bleiben die bestehenden Programmsysteme und angeschlossenen Tool-Umgebungen weitestgehend unberührt von diesen Maßnahmen, so dass von dieser Seite keine zusätzliche Aufwände zu berücksichtigen sind.

Abb. 1: Integriertes Datenmanagement
Das Konzept des Integrierten Datenmanagements wird vervollständigt durch die Anbindung der Datenmodellierung an das zentrale Dictionary-Konzept. Die weitgehende maschinelle Überführung des Datenmodells in Beschreibungen für Datenelemente und -strukturen mit der anschließenden Generierung der Datenbankbeschreibung für das gewünschte Datenbanksystem führt zu einem durchgängigen Verfahren für das Datenmanagement. Zusätzlich erschließen sich durch dieses Vorgehen auch Wege zur rückwärtigen Ableitung von angenäherten Datenmodellen aus den im DataDictionary vorliegenden Datenbankbeschreibungen.
Der Nutzen
Profitieren Sie von unseren Erfahrungen, wir kennen die Werkzeuge, wir kennen die Vorgehensweisen. Schaffen Sie sich die Transparenz in Ihrem Datenmanagement und sichern sich
- Wissen um den Inhalt und den Kontext Ihrer Daten
- Gesicherte Datenmigration und -koexistenz in verteilten Datenumgebungen vom Host bis zum PC
- Einheitliche unternehmensweite Datendefinitionen
- Einheitliche Generierung von logischen und physischen Datenbeschreibungen
- Weniger Redundanzen, mehr Standardisierung
- Kontrolliertes Management gewachsener und Vermeidung zukünftiger Synonyme und Homonyme
- Auswirkungsanalysen bei geplanten Änderungen
- Aufwandsreduzierung im Datenmanagement durch kontrolliertes Re-Use von Datenobjekten
- Integration und Rückkopplung zur Datenmodellierung
- 'Single-Point-Of-Information and -Administration' für das unternehmensweite Datenmanagement
Wir möchten Sie erfolgreich machen. Nutzen Sie unsere Erfahrung.