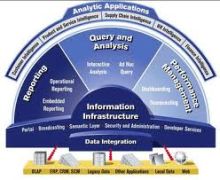
Konzepterfahrung
IS-Infrastruktur-Architektur
- Details
Die Unternehmen müssen immer schneller mit Veränderungsprozessen auf geänderte Marktbedingungen reagieren. Dabei wird der Erfolg kostspieliger IS-Investitionen immer unsicherer. Der Wunsch, die komplexen Geschäftsarchitekturen einfacher zu beherrschen, lässt die Unternehmen nach neuen Wegen der strategischen Informationstechnologie-Planung suchen.
In die Informationstechnologie (IT) eines Unternehmens fließen erhebliche Gelder für die Wartung der vorhandenen Informationssysteme (IS) und für die Anpassung an neue Anforderungen.
Diese Landschaft ist ein komplexes Gebilde aus Architekturelementen (Applikationen, Prozessen, Schnittstellen, Kosten) und Veränderungsfaktoren (Ziele, Programme, Einzelprojekte, Ergebnisse und Effekte), das von vielen Beteiligten gesteuert wird. Eine Fülle von Metadaten beschreibt diese Welt und ihre Zusammenhänge.
Der entscheidende Erfolgsfaktor für die "Beherrschung" der IT ist die Erstellung einer IS-Infrastrukur Architektur. Sie umfasst alle Prozesse (Geschäftsprozesse), alle diese Prozesse unterstützenden Anwendungen, anwendungsübergreifende und systemnahe Softwarekomponenten (Middleware, Datenbanken, Kommunikationssysteme, etc.) mit ihren Beziehungen untereinander. Darüber hinaus enthält sie die Abbildung der Komponenten auf die physische Rechnerlandschaft eines Unternehmens. In der Architekturdarstellung werden Ist- und Soll-Zustand gegenüber gestellt. Der Soll-Zustand ergibt sich dabei einerseits aus konkreten Kundenanforderungen, andererseits aus der Weiterentwicklung der Anwendungs- und Systemarchitektur sowie einer entsprechenden (Jahres-) Planung des Unternehmens, abgeleitet aus seiner IS-Strategie.
Fachliche und technische Zusammenhänge werden auf unterschiedlichen Detaillierungsebenen und aus verschiedenen Sichten heraus dargestellt, so dass einerseits ein Gesamtüberblick geschaffen wird, andererseits aber auch Details erkennbar sind. Dies ermöglicht es, im Unternehmen Verständnis für benachbarte und damit relevante Arbeitsbereiche aufzubauen. Diese globale Betrachtungsweise ist Voraussetzung für ein umfassendes Produkt- und Architektur-Management. Ohne Kenntnis der IS-Infrastruktur Architektur können Auswirkungen von Änderungen oder Neuentwicklungen nur unzureichend abgeschätzt und damit schwer geplant werden. So wird die IS-Infrastruktur Architektur zur Basis für die Priorisierung von IS-Projekten, für Folge- und Risikoabschätzungen, und beeinflusst mittelbar auch die künftigen Betriebskosten.
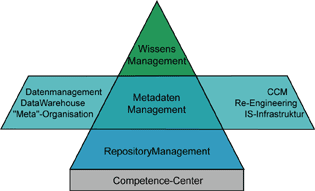
Ein MetadatenManagement-System ist das geeignete Instrument zur Darstellung der komplexen IS-Infrastruktur Architektur. Dabei wird das Metadaten-Informationsmodell zum Abbild der real existierenden Infrastruktur. Ein Repository-System dient als technischer Hintergrund zur Ablage und Auswertung der Architekturdaten.
Unsere Konzepterfahrung umfasst
- Die Erfahrung zum Aufbau einer metadatengestützten IS-Infrastruktur Architektur.
- Das Wissen um die typischen Objekte einer betrieblichen IS-Struktur, und damit das Wissen um den Aufbau der entsprechenden Informationsmodelle.
- Die Erfahrung im Einsatz entsprechender Repository-Systeme zur Aufnahme und Analyse der Architektur-Informationen.
- Die Kenntnisse um die Verfahren, um eine weitgehende maschinelle Population der Metadaten-Umgebung aus den bestehenden Architekturkomponenten zu erreichen.
- Die Erfahrung um die grundlegenden Informationsbedürfnisse zur Analyse der existierenden IS-Infrastruktur Architektur, zur Planung der anstehenden Aufgaben oder zur Erhöhung des Integrationsgrades bestehender Systeme.
Profitieren Sie von unseren Erfahrungen. Lassen Sie sich beraten und kommen Sie schneller an Ihr Ziel.
Change- und Configuration-Management
- Details
Die zunehmende Komplexität in der Anwendungsentwicklung, gekennzeichnet durch viele parallele Projekte, zunehmend in heterogenen Entwicklungsumgebungen, führen zur Anforderung von einheitlichen Vorgehensweisen im gesamten Prozess der Produktentwicklung und Projektabwicklung.
Selbst bei bestehenden Verfahren, vorrangig im Umfeld der host-orientierten Anwendungsentwicklung angesiedelt, besteht der Wunsch und in der Regel auch das Potential für Verbesserungen, insbesondere durch standardisierte Abläufe auf allen Systemplattformen und Integration entsprechender Software-Werkzeuge, abgeleitet aus Fragen, wie:
- Haben Sie die Kontrolle über alle durchgeführten Änderungen im Life Cycle eines Anwendungsobjektes und können revisionssichere Nachweise führen?
- Ist die Konsistenz der Änderungsstände aller an der Anwendung beteiligten Systemkomponenten (Release) auch nach Änderungen gewährleistet, und dies auch über heterogen zusammenwirkende Systeme hinweg?
- Kennen Sie definierte Entwicklungsstufen und Übergabeverfahren von der Entwicklung bis zur Produktionsfreigabe?
- Wie hoch ist der Aufwand, um die änderungsrelevanten Systemelemente aus der fachlichen Bedarfsanforderung abzuleiten?
- Stehen die Informationen angeschlossener Source- und Konfigurationsmanagement-Systeme allen relevanten Aufgabenträgern an ihren Arbeitsplätzen zur Verfügung?
- Können Sie die Seiteneffekte von Änderungen in Ihre Planungen einbeziehen?
- Können Sie zentral den aktuellen Projektfortschritt und den Entwicklungsstand erkennen?
- ........
Der Lösungsansatz
Die Einführung eines Repository-basierten Change- und ConfigurationManagements (CCM) versetzt Sie in die Lage, diesen Fragen gezielte Antworten entgegen zu setzen.
Dabei steht das ChangeManagement für den gesteuerter Änderungsprozess über die Entwicklungsstufen (z.B. in_Entwicklung; in_Test, in_Produktion), das VersionsManagement für die Dokumentation und Nachvollziehbarkeit der konkreten Änderungsinhalte, und das ConfigurationManagement weist den Status einer Sammlung von Objekten, einer Konfiguration oder eines Releases aus, einschließlich des aktuellen Status der zugehörigen Elemente.
Die Vielzahl der Plattformen, Betriebssysteme, Datenbanken (zentral und dezentral), Entwicklungsumgebungen und -paradigmen erfordern unterschiedliche Entwicklungsteams mit unterschiedlichsten KnowHow und Vorgehensweisen. Um dies sicher zu beherrschen, benötigen Sie ein permanent aktuelles Bild, welche Komponenten, Klassen und Elemente an welchen Lokationen existieren, wie sie miteinander gekoppelt sind und in Verbindung stehen und nicht zuletzt, in welchem Status sie sich momentan befinden. Damit sind quasi die Metadaten eines CCM-Systems angesprochen. In einem Repository abgelegt dienen sie einerseits der Planung, Steuerung und Kontrolle des Change-, Versions- und ConfigurationManagement und werden andererseits aus diesen Prozessen heraus auch wieder aktualisiert.
Die besondere Leistungsfähigkeit unserer CCM-Konzepte liegt in der Kopplung des Repository-basierten Ansatzes mit den in der Regel vorhandenen CCM-Toolumgebungen. Im Zusammenspiel mit Source- oder ConfigurationManagment-Systemen entsteht ein CCM, das allen obigen Fragen gerecht wird. So lassen sich beispielsweise mit dem Repository-Wissen um die Anwendungen und deren Zusammenhänge aus den fachlichen Änderungswünschen die relevanten Arbeitspakete für die anzupassenden Systemelemente ableiten (auch über heterogene Welten hinweg) und in einem automatisierten Schritt dem Checkout-Mechanismus der beteiligten Sourcemanagement-Systeme zuführen.
In jedem Falle wird flexibel auf die vorhandene Situation und die spezifischen Anforderungen Ihres Unternehmens eingegangen. Unsere Erfahrungen sind breit gefächert und führen auch für Sie zu akzeptablen Lösungen.
Unabhängig von der Frage, ob das Repository die aktive Rolle in der Steuerung der CCM-Abläufe übernimmt oder als passives Informationsmedium Ihre bestehenden CCM-Umgebungen begleitend unterstützt, werden die angestrebten Ziele erreicht:
- Einheitliches kontrolliertes CCM-Verfahren für zentrale und dezentrale Entwicklungsumgebungen (Grundlage für angestrebte Zertifizierungen)
- Revisionssicherer Nachweis aller Veränderungen im Life Cycle der Anwendungssysteme
- Integration unterschiedlicher Entwicklungsparadigmen in ein einheitliches zielsystemgerechtes Produktionsfreigabeverfahren
- Erkennen und Beherrschen von Konfliktsituationen in Multi-Projektumgebungen
- Stabile Produkte und hohe Verfügbarkeiten durch verringerte Störanfälligkeit
- Verlässliche Planungs- und Nachkalkulationsbasis
- Sicheres Reagieren auch in Notfallsituationen
- Geordneter Fallback im Bedarfsfalle
- Automatisierung von Teilprozessen
- Optimierte Unterstützung der Anwendungsentwicklung
- Vollständige Projektinformationen für alle Aufgabenträger
- Reduzierung von Wartungs- und Koordinierungsaufwänden
Sichern auch Sie sich diese Vorteile. Gerne zeigen wir Ihnen die Möglichkeiten in Ihrem Unternehmen unter Berücksichtigung Ihrer bestehenden Umgebungen und Anforderungen.
Wir wollen Ihren Erfolg. Setzen Sie auf unsere Kompetenz.DataWarehouse
- Details
Steht Ihr DataWarehouse auf stabilen Säulen?
Moderne DataWarehouse Umgebungen müssen eine große Anzahl verschiedenster Datenbanken, Dateisysteme, Tools and Applikationen integrieren, wobei diese Komponenten in unterschiedlichster Weise strukturiert und beschrieben sind. Die Anwender im Hause sollen eine weitgehende Autonomie in der Nutzung dieser Informationen haben und in die Lage versetzt werden, Geschäftsprozesse und Märkte zu analysieren, Entscheidungen zu treffen und Strategien zu entwickeln. Wir erkennen, wie wichtig hierfür korrekte, vollständige, aktuelle und direkt nutzbare Informationen sind.
Und wie steht es in Ihrem bestehenden oder geplanten DataWarehouse mit diesen Anforderungen? Die Daten in einem DataWarehouse sind immer transformiert, integriert, aggregiert, kumuliert und aufbereitet. Somit hängen richtige Analysen und Entscheidungen unmittelbar ab von der Qualität der einfließenden Daten und der Qualität der angesprochenen Aufbereitungsprozesse. Inwieweit erzielen Sie für Ihre Anwender die notwendige Transparenz in die Sicherstellung dieser Qualitätsanforderungen, um so den mittel- und langfristigen Erfolg des DataWarehouse zu manifestieren?
Mit dem DataWarehouse wird neben der operativen Welt der originären Datenbestände mit daraus selektierten Daten ein dispositives Umfeld aufgebaut, dessen Ableitung mit Herkunft, Umsetzung und neuer Struktur immer nachvollziehbar bleiben muss. Nur so kann sichergestellt werden, dass beispielsweise bei notwendigen Anpassungen im operativen Datenbestand die daraus resultierenden Änderungen in der DataWarehouse Umgebung präventiv angegangen werden können.
Instrumente für diese 'Qualitätssicherung' sind ein integriertes Metadaten- und RepositoryManagement, mit denen alle Informationen über die Strukturen, Inhalte und Abhängigkeiten der DataWarehouse Komponenten festgehalten werden. Dabei sind nicht nur die herkömmlichen technischen Metadaten (wie Tabellen- und Satzstrukturen, Umsetzungstabellen und -regeln, etc.) relevant, sondern auch die semantischen (fachlichen) Metadaten, die als fachlich orientierte Beschreibung die Definitionen und Inhalte von Business-Objekten, deren Bereitstellung und vieles mehr wiedergeben. Auch die auf der Business-Ebene zusammengeführten mehrdimensionalen Datenwürfel (Cubes) werden erst über ihre semantischen Metadaten als flexible Auswertebasis tauglich.
Dabei ist nicht von entscheidender Bedeutung die Anzahl der definierten Metadatenebenen (z.B. 3 Ebenen mit Operational-, DataWarehouse- und Business-Layer oder 4 Ebenen mit technischlogisch, fachlich-konzeptionell, DataMart- und Unternehmens-Layer) (siehe Abb. 1), sondern die Durchgängigkeit des MetadatenManagements über alle Ebenen hinweg und auch innerhalb der jeweilige Ebene.
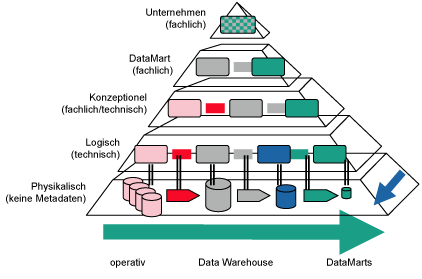
Abbildung 1: Metadatenebenen
Dies vollzieht sich in einem zentralen Metadatenmodell. Seine Struktur bestimmt sich im wesentlichen aus den Integrationserfordernissen der verschiedenen Metadaten der DataWarehouse-Umgebung und den Informationsbedürfnissen der Anwender.
Die Möglichkeit, mit einem zentralen Modell die Metadaten der unterschiedlichen am DataWarehouse Prozess beteiligten Tools in einer einheitlichen Semantic in einer Metadatenbasis zusammenzuführen bzw. aus dieser heraus wiederum auch zu versorgen, ist ein entscheidender Faktor für die Qualitätssicherung des DataWarehouse und seiner Prozesse.
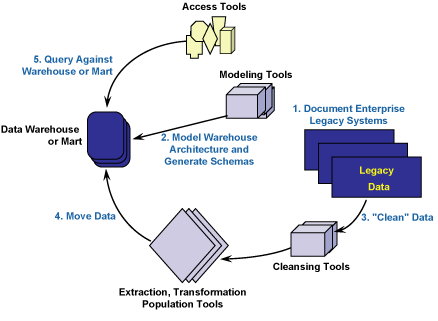
Abbildung 2: DataWarehouse-Tools
Die zunehmenden Integrationsanforderungen innerhalb der DataWarehouse Welt förderten die Bemühungen um eine weitergehende Standardisierung der Metadaten in diesem Umfeld. So wurden einheitliche übergreifende Standard-Metamodelle definiert, wobei sich inzwischen das Common Warehouse Model (CWM) der Object Management Group (OMG) als Repräsentationsmodell durchgesetzt hat. Ebenso ist heute das XML Metadata Interchange Format (XMI) ein anerkannter Standard für den Austausch von Metadaten zwischen den beteiligten Komponenten des DataWarehouse.
Das technische Umfeld ist verfügbar. Stellen Sie sicher, dass Ihr Data Warehouse auf stabilen Säulen steht. Ein MetadatenManagement ist dafür der Dreh- und Angelpunkt. So erreichen Sie:
- den ‚Single-Point-of-Truth', aus dem heraus alle Beschreibungen gefunden werden zur Verwaltung, Nutzung und Aktualisierung des DataWarehouse
- die Eliminierung von Redundanzen und Inkonsistenzen
- die optimale Koordination aller am DataWarehouse-Prozess Beteiligten
- eine Vereinheitlichung der Schnittstellen
- eine Beherrschbarkeit des komplexen Systems
- eine Ableitung weitergehender Synergien auf Basis der verfügbaren Metadaten
- eine Reduzierung der Wartungsaufwände für die konsistente Bereithaltung des DataWarehouse, denn
- auch im DataWarehouse fallen 70 % der Aufwände in der Wartungsphase an
- kein DataWarehouse wird mehr als 1 Jahr ohne Veränderung genutzt
- der Verlust von Aktualität ist schleichend, oft unbemerkt, die Auswirkung fatal
Wir kennen die Modelle, wir kennen die Verfahren, wir kennen die Standards. Wir haben die Erfahrungen, die Ziele zu erreichen und die Restriktionen zu beseitigen.
Wir möchten Sie erfolgreich wissen. Bauen Sie auf unsere Erfahrung.
Integriertes Datenmanagement
- Details
Überblicken Sie Ihre Datenbestände auf allen Plattformen?
In allen Unternehmen stehen heute umfangreiche Datenbestände zur Verfügung. Sie sind über Jahrzehnte hinweg in unterschiedlichen Projekten entstanden. Sie sind nicht mehr nur zentral abgelegt, sondern in heterogenen Umgebungen den heutigen Anwendungserfordernissen entsprechend auf unterschiedlichen Systemplattformen vorhanden. Sie stammen aus unterschiedlichen Quellen, werden zwischen den Systemen transferiert und kopiert und basieren nur in seltenen Fällen auf einer gemeinsamen Datenarchitektur.
Der Informatiker Max Vetter hatte in den 80-er Jahren als Jahrhundertproblem der Informatik 'die Bewältigung des Datenchaos, das infolge unkontrolliert gewachsener Datenbestände fast überall entstanden ist' definiert. Das Jahrhundert, das er meinte, ist zuende. Ist das Problem inzwischen gelöst?
Auch heute kämpfen viele Unternehmen mit Redundanzen, Synonymen und Homonymen als Altlasten und hinterfragen die Konsistenz Ihrer Daten über die verschiedenen Systeme (Datenbank- und Dateisysteme in unterschiedlichen Rechnerumgebungen) hinweg.
Dem Überfluss an Daten steht oft genug ein Informationsmangel gegenüber hinsichtlich:
- Beschreibung und Kontext
- Korrektheit
- Vollständigkeit
- Aktualität
- Verwendung.
Die Vielzahl parallel laufender Projekte und die Notwendigkeit, auf die Anpassungswünsche der unterschiedlichen Fachbereiche schnell, flexibel und separat eingehen zu müssen, lassen Forderungen nach einer Verbesserung der Gesamtsituation und Reduzierung der enormen Koordinationsaufwände aufkommen.
Der Lösungsansatz Ein integriertes Datenmanagement in einem zentralen DataDictionary oder Repository wird auch in Ihrem Unternehmen zum Erfolg führen.
Ein solches integratives Gesamtsystem wird eine verbesserte Informationsversorgung ermöglichen und die Hauptaufgaben eines Datenmanagements gewährleisten:
- Schaffung einer einheitlichen Begriffswelt innerhalb des Unternehmens.
- Stabile bereichsübergreifende Datenhaltung.
- Verfügbarkeit eines zuverlässigen Informationsangebots für alle Aufgabenträger.
- Unterstützung bei der Entwicklung und Pflege von Datenmodellen.
- Planungsgrundlage für den langfristigen Informationsbedarf.
- Strategische Basis für eine durchgängige Datenarchitektur.
Mit der unternehmensweiten, redundanzfreien und möglichst sprachunabhängigen Ablage aller Datenobjekte im zentralen DataDictionary/Repository entsteht eine Umgebung für die Erstellung, Beschreibung und Verwaltung der Datenbestände. Ergänzt um sprach- oder datenbankspezifische Elemente erfolgt die Generierung konsistenter physischer Datenbeschreibungen für Anwendungen und Datenbanken aus dem zentralen Informationspool.
Die Vorgehensweise
Da es um die Optimierung bestehender Systeme geht, ist die zentrale Aufgabe des ersten Projektschrittes die Übernahme der bestehenden Datenelemente und -strukturen, sei es aus Copy-Bibliotheken, Datenbank-Katalogen, Programmsourcen, etc. oder auch aus anderen untergeordneten (gfs. toolspezifischen) Dictionary-Systemen. Ein weitestgehend maschinelles Verfahren mittels entsprechender Interfaces garantiert einen überschaubaren zeitlichen Rahmen für diese Arbeiten.
Die im Übernahmeverfahren erkannten und gekennzeichneten Redundanzen, Synonyme und Homonyme lassen sich anschließend transparent verwalten und in Planungen und Aktionen zu deren Eliminierung einbinden. Mit optionalen nachfolgenden Projektschritten werden wiederverwendbare Datenobjekte und generelle Datentypen herausgearbeitet.
Durch die maschinelle Generierung eines 'Status quo' bleiben die bestehenden Programmsysteme und angeschlossenen Tool-Umgebungen weitestgehend unberührt von diesen Maßnahmen, so dass von dieser Seite keine zusätzliche Aufwände zu berücksichtigen sind.

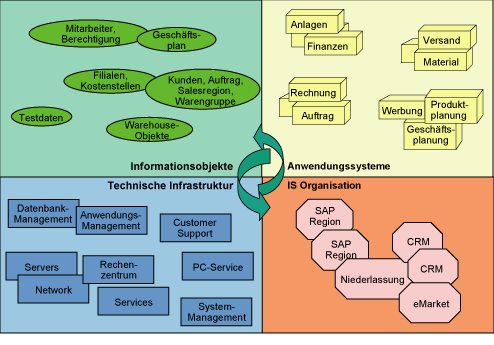
Abb. 1: Integriertes Datenmanagement
Das Konzept des Integrierten Datenmanagements wird vervollständigt durch die Anbindung der Datenmodellierung an das zentrale Dictionary-Konzept. Die weitgehende maschinelle Überführung des Datenmodells in Beschreibungen für Datenelemente und -strukturen mit der anschließenden Generierung der Datenbankbeschreibung für das gewünschte Datenbanksystem führt zu einem durchgängigen Verfahren für das Datenmanagement. Zusätzlich erschließen sich durch dieses Vorgehen auch Wege zur rückwärtigen Ableitung von angenäherten Datenmodellen aus den im DataDictionary vorliegenden Datenbankbeschreibungen.
Der Nutzen
Profitieren Sie von unseren Erfahrungen, wir kennen die Werkzeuge, wir kennen die Vorgehensweisen. Schaffen Sie sich die Transparenz in Ihrem Datenmanagement und sichern sich
- Wissen um den Inhalt und den Kontext Ihrer Daten
- Gesicherte Datenmigration und -koexistenz in verteilten Datenumgebungen vom Host bis zum PC
- Einheitliche unternehmensweite Datendefinitionen
- Einheitliche Generierung von logischen und physischen Datenbeschreibungen
- Weniger Redundanzen, mehr Standardisierung
- Kontrolliertes Management gewachsener und Vermeidung zukünftiger Synonyme und Homonyme
- Auswirkungsanalysen bei geplanten Änderungen
- Aufwandsreduzierung im Datenmanagement durch kontrolliertes Re-Use von Datenobjekten
- Integration und Rückkopplung zur Datenmodellierung
- 'Single-Point-Of-Information and -Administration' für das unternehmensweite Datenmanagement
Wir möchten Sie erfolgreich machen. Nutzen Sie unsere Erfahrung.
Re-Engeneering
- Details
Schöpfen Sie alle Vorteile aus Ihren bestehenden IT-Systemen?
Zunehmende Anforderungen an die IS-Systeme verlangen mehr Flexibilität. Die Applikationen den neuen Gegebenheiten schnell und kostengünstig anzupassen, ist eine Herausforderung an Budget, Ressourcen und Technik.
Ihre vorhandenen Applikationen sind wertvolles Betriebskapital. Unsere Re-Engineering Konzepte helfen Ihren, das darin investierte Kapital und Know how zu erhalten.
Re-Engineering bedeutet die Implementieren neuer Leistungs- und Funktionsanforderungen, Modernisieren von Applikationen, Durchführen von Umstellungen und Migrationen, Erstellen von Nachdokumentationen und Verbesserung der Wartbarkeit der Programme.
Die Lebensdauer der bestehenden Anwendungen wird dadurch verlängert und die bewirtschafteten Daten bleiben dem Unternehmen erhalten. Der Wartungsaufwand lässt sich um belegbare Größenordnungen reduzieren.
Re-Engineering wird als Oberbegriff für alle Verfahren und Hilfsmittel verstanden, deren Inhalt die qualitative Verbesserung und Aufbereitung bestehender Applikationen ist bzw. alle Maßnahmen, die der verbesserten Pflege und Wartung von Alt-Anwendungssystemen dienen. Es wird Wert gelegt auf sehr praxisorientierte Verfahren, mit denen sich auch kurzfristige nachweisbare Erfolge erzielen lassen.
Fast alle Unternehmen, die über viele Jahre IS-Systeme im Einsatz haben, müssen sich mit den Auswirkungen ihrer Alt-Anwendungen auseinandersetzen. Wartungs-Aktivitäten binden große Teil der vorhandenen Personalkapazitäten. Hinzu kommen oft 'äußere' Ereignisse wie Migrationen aufgrund von Unternehmens-Reorganisationen oder Firmenzusammenschlüssen, die den Blick auf die existierenden Applikationen lenken und den Wunsch nach einem tieferen Verständnis für diese Landschaften aufkommen lassen.
Fragen hinsichtlich der Vollständigkeit der Dokumentation, der Aktualität der Verwendungsnachweise, der Durchgängigkeit der Standards, nach den Anwendungszusammenhängen (wie Datei- und Feldverwendungen, wechselseitige Programmaufrufe oder tangierte Systemelemente bei einer Änderung) können nur unzutreffend oder unter hoher Unsicherheit beantwortet werden.
Die Alt-Anwendungen sollen nicht einfach zur Seite geschoben werden. Sie sind nicht nur Altlasten, sondern enthalten zum Teil auch versunkene Schätze in Form von wiederverwendbaren Konstrukten und liefern ihren aktuellen Beitrag in dem betrieblichen Informationssystem. Sie laufen seit Jahren fehlerarm und stabil und sind dem Benutzer vertraut. Mehr den je besteht heute die Notwendigkeit, diese stabilen Anwendungsfunktionen unter den Aspekten eines EAI (Enterprise Application Integration) in neue Umgebungen einzubinden und auf neuen Plattformen in einer neuen Infrastruktur verfügbar zu machen.
Die grundlegenden Anforderungen eines Re -Engineering-Ansatzes beziehen sich somit auf das bestehende Applikationsumfeld.
- Mit dem Bewusstsein, dass die Stabilität und Lebensdauer einer Applikation in einem hohen Maße abhängig ist von der Qualität ihrer Dokumentation, wird die Applikationen mit ihren Systemelementen und den Beziehungsstrukturen vollständig, übersichtlich, stets aktuell und nachprüfbar beschrieben.
- Mit einem verbesserten Anwendungsverständnis werden die wiederverwendbaren Software-Konstrukte erkannt, um so Zeit-, Personal- und Kosteneinsatz - sowohl bei Wartung als auch bei Neuentwicklungen - zu senken.
- Über fundierte Auswirkungsanalysen werden die Fernwirkungen von Änderungen vollständig überschaubar und damit die Wartungssicherheit gesteigert.
- Standards und Normen werden in ihrer Verwendung und Durchgängigkeit transparent und erweiterbar.
- Redundante oder nicht mehr verwendete Anwendungsteile werden erkannt und in kontrollierter Form eliminierbar.
- In einem zentralen Repository werden die Informationen aufgenommen und verwaltet.
Da die einzig objektiv richtige 'Wahrheit' über die bestehenden Applikationen zunächst einmal nur in den Sourcen liegen kann, liefert eine maschinelle Analyse (mittels Parser, Scanner, Interfaces) mit einem überschaubaren Aufwand fehlerfreie und aktuelle Informationen. Ein Repository mit beliebig definierbaren Objektklassen und Beziehungsstrukturen lässt dabei den unternehmensspezifischen Zuschnitt des Vorgehens zu.
Die analysierten Ergebnisse wurden strukturiert, verknüpft, wiederauffindbar und auswertbar im Repository abgelegt.
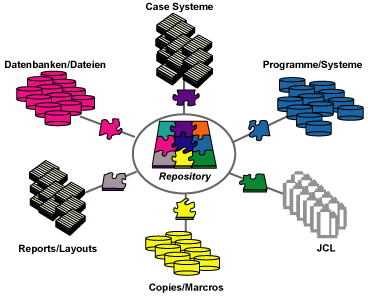
Abb. 1:Überblick auf "Knopfdruck"
So werden die Zielsetzungen des Re-Engineerings erreicht:
- Die Dokumentation entspricht jederzeit dem Produktionsumfeld.
- Die Ergebnisse sind mittels Auswertungen unmittelbar textlich oder graphisch visualisiert zugänglich
- Die Wartung ist nachweislich stabil und sicherer, auch größere Umstellungen werden planbar und aufwandsmäßig einschätzbar, Kosten-/Nutzenüberlegungen für Wartungsaufträge konkreter.
- Standards werden vereinheitlicht und durchgängig angewendet.
- Es können wiederverwendbare Module und Services herausgearbeitet werden.
- Es können Bereinigungen vorgenommen werden, indem überflüssige Sourcen erkannt und fehlende Beschreibungen ergänzt werden..
- Redundanzen können eliminiert bzw. kontrolliert werden.
- Die Wartungsaufwände verringern sich in dem transparenten und verbesserten Umfeld.
- Und nicht zuletzt werden neue Mitarbeiter im Wartungsumfeld wesentlich schneller produktiv.
Das Re-Engineering liefert Ihnen das Know-How über die vorhandenen Applikationen und deren Internas, um so schnell, zuverlässig und den Anforderungen des Fachbereiches angemessen, reagieren zu können. Durch hohe Qualität und hohe Produktivität in diesem Umfeld wird eine gute gesicherte Position geschaffen für weitergehende Überlegungen hinsichtlich der zukünftigen Anwendungsentwicklung.
Nicht zuletzt ergibt sich aus diesem Re-Engineering Konzept eine Integration bestehender und neuer Verfahren, Anwendungen, Projekte und Produkte durch gleiche durchgängige Standards und Normen und mit dieser Eigendynamik des Re-Engineering wird dieser Ansatz somit integraler Bestandteil des Software-Engineerings Ihres Unternehmens.
Die Effekte gehen allerdings noch weit über die geschilderten Ergebnisse hinaus. Auch Projekte wie beispielsweise DataWarehouse, Datenmanagement, IS-Infrastruktur sind nur auf der Basis gesicherter Erkenntnisse aus den bestehenden IT-Systemen denkbar. Wir geben Ihnen gerne praxiserprobte Beispiele weitergehender Synergien aufbauend auf den erkannten Metadaten des Re-Engineerings.
Ebenso können wir Ihnen gerne aus unseren Praxiserfahrungen heraus quantifizierbare Nutzenpotentiale für Personal- und Sachressourcen aufzeigen.
Profitieren Sie von unseren Erfahrungen. Lassen Sie sich beraten und kommen Sie schneller an Ihr Ziel.